User Guide
Hatchet is a Python tool that simplifies the process of analyzing hierarchical performance data such as calling context trees. Hatchet uses pandas dataframes to store the data on each node of the hierarchy and keeps the graph relationships between the nodes in a different data structure that is kept consistent with the dataframe.
Data structures in hatchet
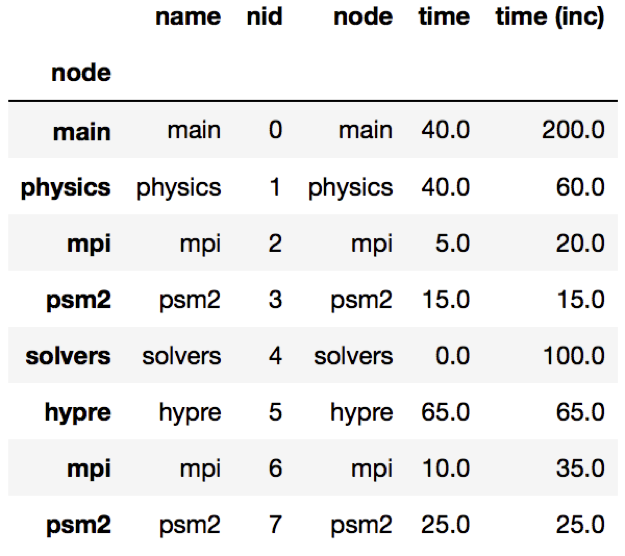
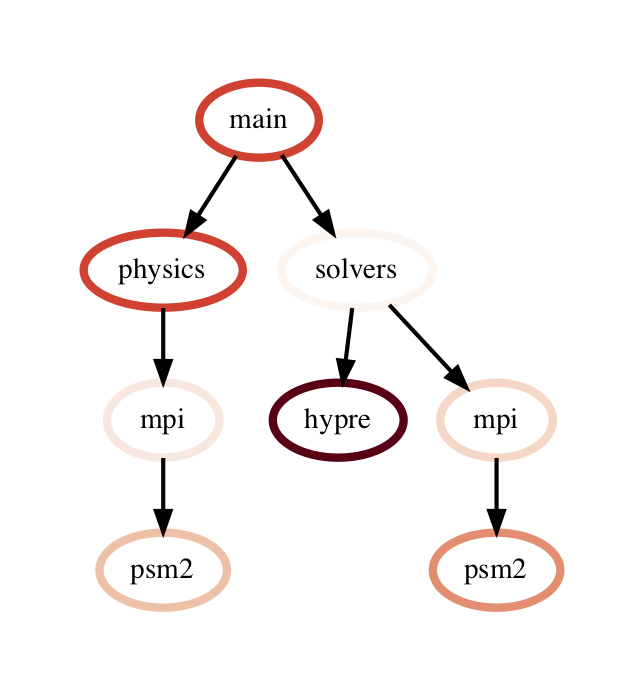
Hatchet’s primary data structure is a GraphFrame, which combines a
structured index in the form of a graph with a pandas dataframe. The images
on the right show the two objects in a GraphFrame – a Graph object (the
index), and a DataFrame object storing the metrics associated with each
node.
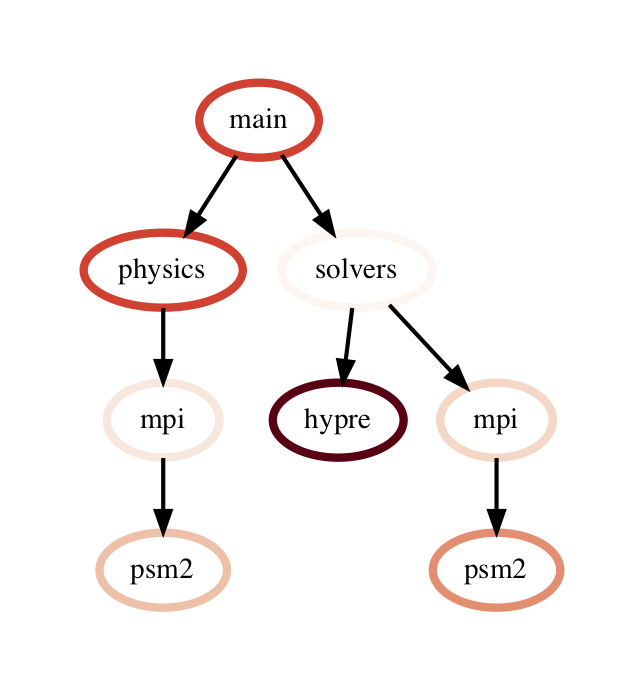
Graphframe stores the performance data that is read in from an HPCToolkit database, Caliper Json or Cali file, or gprof/callgrind DOT file. Typically, the raw input data is in the form of a tree. However, since subsequent operations on the tree can lead to new edges being created which can turn the tree into a graph, we store the input data as a directed graph. The graphframe consists of a graph object that stores the edge relationships between nodes and a dataframe that stores different metrics (numerical data) and categorical data associated with each node.
Graph: The graph can be connected or disconnected (multiple roots) and each node in the graph can have one or more parents and children. The node stores its frame, which can be defined by the reader. The call path is derived by appending the frames from the root to a given node.
Dataframe: The dataframe holds all the numerical and categorical data associated with each node. Since typically the call tree data is per process, a multiindex composed of the node and MPI rank is used to index into the dataframe.
Reading in a dataset
One can use one of several static methods defined in the GraphFrame class to
read in an input dataset using hatchet. For example, if a user has an
HPCToolkit database directory that they want to analyze, they can use the
from_hpctoolkit method:
import hatchet as ht
if __name__ == "__main__":
dirname = "hatchet/tests/data/hpctoolkit-cpi-database"
gf = ht.GraphFrame.from_hpctoolkit(dirname)
Similarly if the input file is a split-JSON output by Caliper, they can use
the from_caliper method:
import hatchet as ht
if __name__ == "__main__":
filename = ("hatchet/tests/data/caliper-lulesh-json/lulesh-annotation-profile.json")
gf = ht.GraphFrame.from_caliper(filename)
Examples of reading in other file formats can be found in Analysis Examples.
Visualizing the data

When the graph represented by the input dataset is small, the user may be interested in visualizing it in entirety or a portion of it. Hatchet provides several mechanisms to visualize the graph in hatchet. One can use the tree() function to convert the graph into a string that can be printed on standard output:
print(gf.tree())
One can also use the to_dot() function to output the tree as a string in the Graphviz’ DOT format. This can be written to a file and then used to display a tree using the dot or neato program.
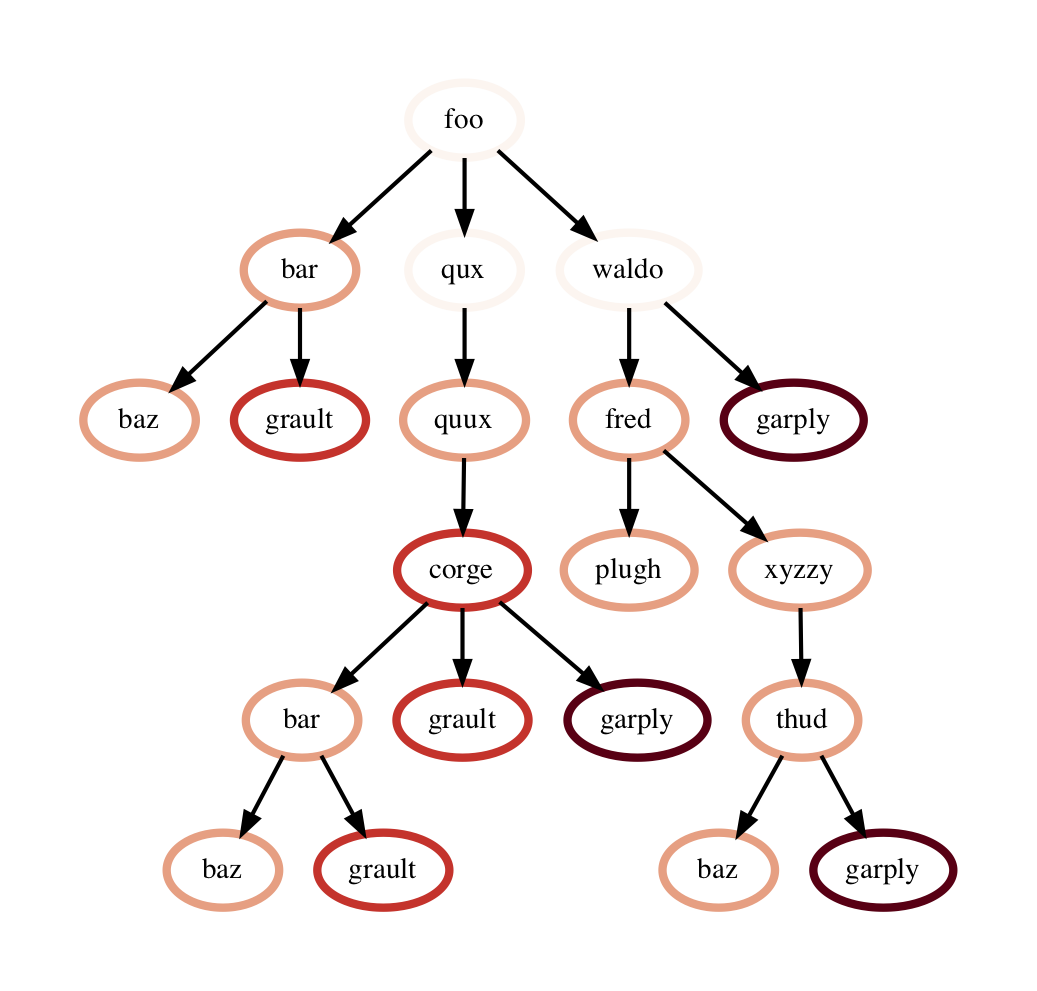
with open("test.dot", "w") as dot_file:
dot_file.write(gf.to_dot())
$ dot -Tpdf test.dot > test.pdf
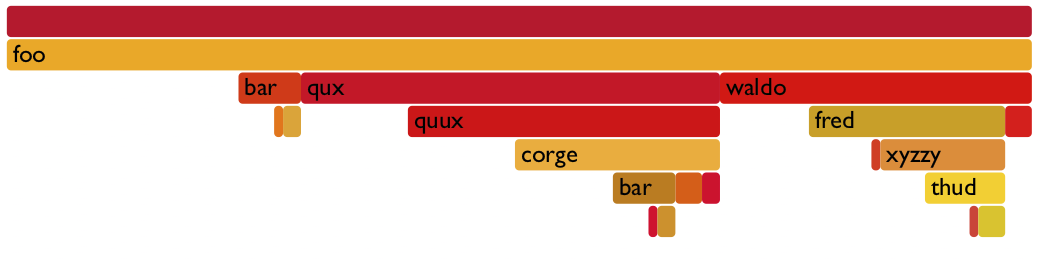
One can also use the to_flamegraph function to output the tree as a string
in the folded stack format required by flamegraph. This file can then be used to
create a flamegraph using flamegraph.pl.
with open("test.txt", "w") as folded_stack:
folded_stack.write(gf.to_flamegraph())
$ ./flamegraph.pl test.txt > test.svg
One can also print the contents of the dataframe to standard output:
pd.set_option("display.width", 1200)
pd.set_option("display.max_colwidth", 20)
pd.set_option("display.max_rows", None)
print(gf.dataframe)
If there are many processes or threads in the dataframe, one can also print a cross section of the dataframe, say the values for rank 0, like this:
print(gf.dataframe.xs(0, level="rank"))
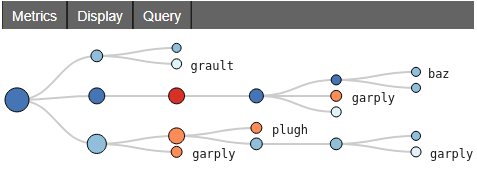
One can also view the graph in Hatchet’s interactive visualization for Jupyter. In the Jupyter visualization shown below, users can explore their data by using their mouse to select and hide nodes. For those nodes selected, a table in the the upper right will display the metadata for the node(s) selected. The interactive visualization capability is still in the research stage, and is under development to improve and extend its capabilities. Currently, this feature is available for the literal graph/tree format, which is specified as a list of dictionaries. More on the literal format can be seen here.
roundtrip_path = "hatchet/external/roundtrip/"
%load_ext roundtrip
literal_graph = [ ... ]
%loadVisualization roundtrip_path literal_graph
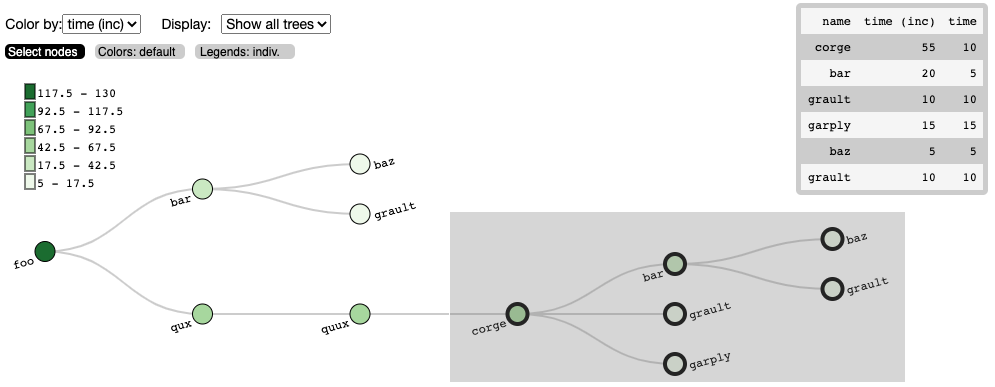
Once the user has explored their data, the interactive visualization outputs the corresponding call path query of the selected nodes.
%fetchData myQuery
print(myQuery) # displays [{"name": "corge"}, "*"] for the selection above
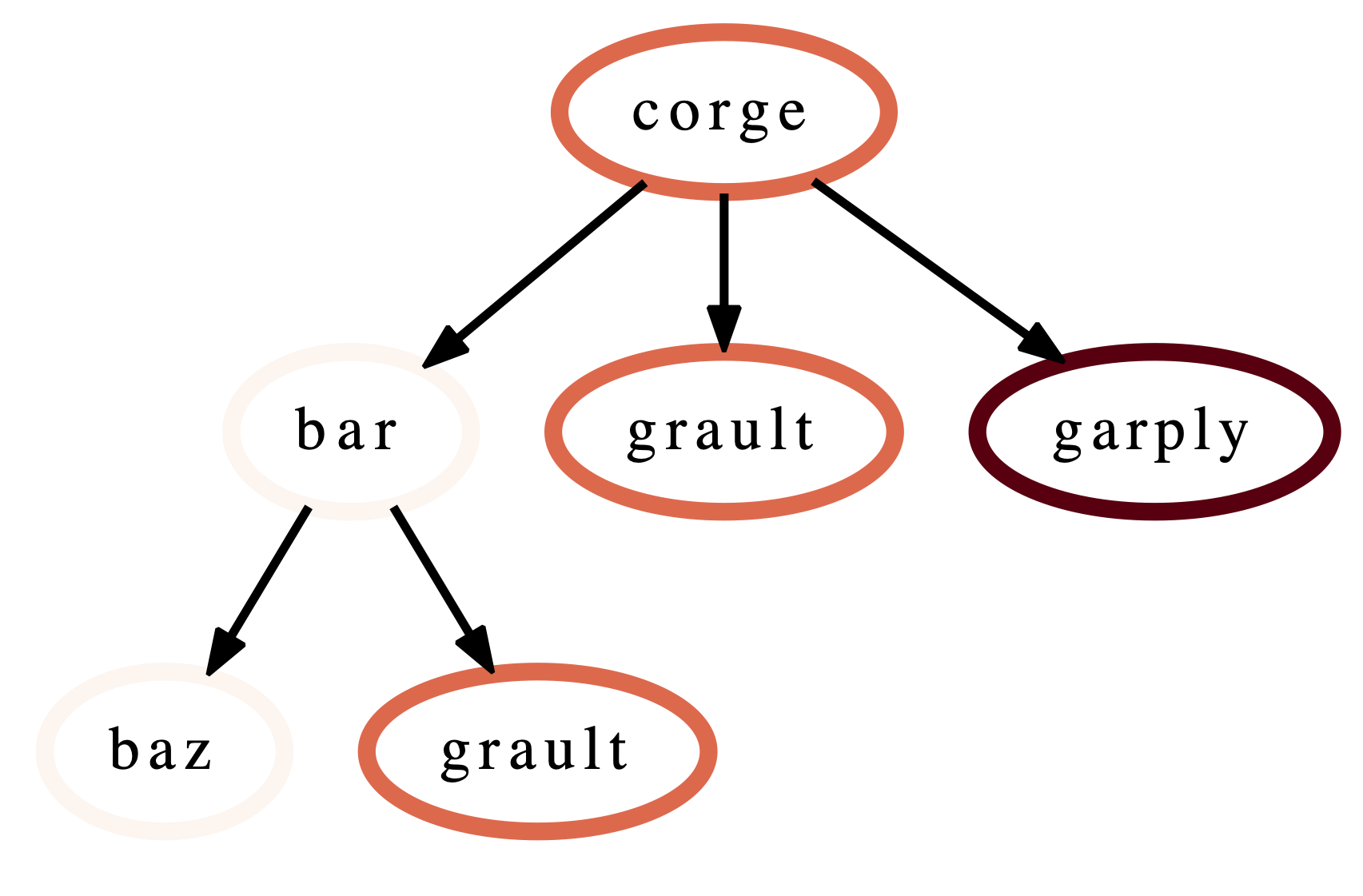
This query can then be integrated into future workflows to automate the
filtering of the data by the desired query in a Python script. For the
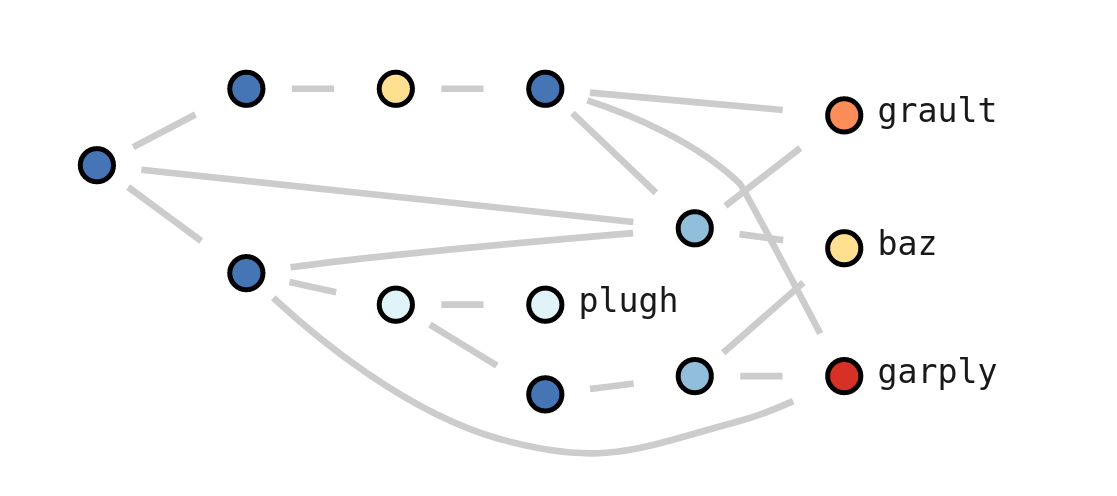
selection above, we save the resulting query as a string and pass it to
Hatchet’s filter() function to filter the input literal graph. An example
code snippet is shown below, with the resulting filtered graph shown on the
right.
myQuery = [{"name": "corge"}, "*"]
gf = ht.GraphFrame.from_literal(literal_graph)
filter_gf = gf.filter(myQuery)
An example notebook of the interactive visualization can be found in the docs/examples/tutorials directory.
Dataframe operations
filter: filter takes a user-supplied function or query object and
applies that to all rows in the DataFrame. The resulting Series or DataFrame is
used to filter the DataFrame to only return rows that are true. The returned
GraphFrame preserves the original graph provided as input to the filter
operation.
filtered_gf = gf.filter(lambda x: x['time'] > 10.0)
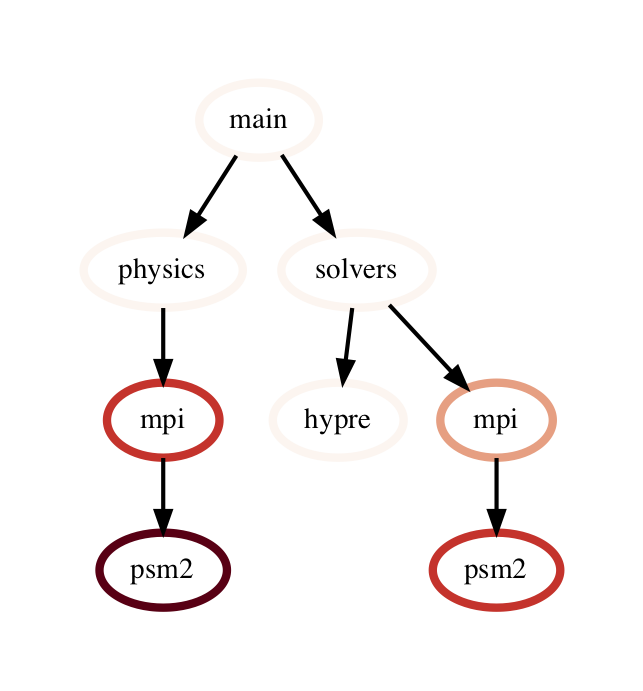
The images on the right show a DataFrame before and after a filter operation.
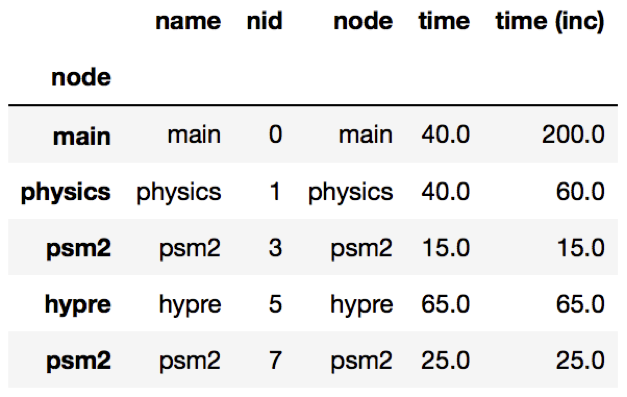
An alternative way to filter the DataFrame is to supply a query path in the form of a query object. A query object is a list of abstract graph nodes that specifies a call path pattern to search for in the GraphFrame. An abstract graph node is made up of two parts:
A wildcard that specifies the number of real nodes to match to the abstract node. This is represented as either a string with value “.” (match one node), “*” (match zero or more nodes), or “+” (match one or more nodes) or an integer (match exactly that number of nodes). By default, the wildcard is “.” (or 1).
A filter that is used to determine whether a real node matches the abstract node. In the high-level API, this is represented as a Python dictionary keyed on column names from the DataFrame. By default, the filter is an “always true” filter (represented as an empty dictionary).
The query object is represented as a Python list of abstract nodes. To specify both parts of an abstract node, use a tuple with the first element being the wildcard and the second element being the filter. To use a default value for either the wildcard or the filter, simply provide the other part of the abstract node on its own (no need for a tuple). The user must provide at least one of the parts of the above definition of an abstract node.
The query language example below looks for all paths that match first a single node with name solvers, followed by 0 or more nodes with an inclusive time greater than 10, followed by a single node with name that starts with p and ends in an integer and has an inclusive time greater than or equal to 10. When the query is used to filter and squash the the graph shown on the right, the returned GraphFrame contains the nodes shown in the table on the right.

Filter is one of the operations that leads to the graph object and DataFrame
object becoming inconsistent. After a filter operation, there are nodes in the
graph that do not return any rows when used to index into the DataFrame.
Typically, the user will perform a squash on the GraphFrame after a filter
operation to make the graph and DataFrame objects consistent again. This can be
done either by manually calling the squash function on the new GraphFrame
or by setting the squash parameter of the filter function to True.
query = [
{"name": "solvers"},
("*", {"time (inc)": "> 10"}),
{"name": "p[a-z]+[0-9]", "time (inc)": ">= 10"}
]
filtered_gf = gf.filter(query)
drop_index_levels: When there is per-MPI process or per-thread
data in the DataFrame, a user might be interested in aggregating the data in
some fashion to analyze the graph at a coarser granularity. This function
allows the user to drop the additional index columns in the hierarchical index
by specifying an aggregation function. Essentially, this performs a
groupby and aggregate operation on the DataFrame. The user-supplied
function is used to perform the aggregation over all MPI processes or threads
at the per-node granularity.
gf.drop_index_levels(function=np.max)
calculate_inclusive_metrics: When a graph is rewired (i.e., the parent-child connections are modified), all the columns in the DataFrame that store inclusive values of a metric become inaccurate. This function performs a post-order traversal of the graph to update all columns that store inclusive metrics in the DataFrame for each node.
Graph operations
traverse: A generator function that performs a pre-order traversal of the graph and generates a sequence of all nodes in the graph in that order.
squash: The squash operation is typically performed by the user after a
filter operation on the DataFrame. The squash operation removes nodes from
the graph that were previously removed from the DataFrame due to a filter
operation. When one or more nodes on a path are removed from the graph, the
nearest remaining ancestor is connected by an edge to the nearest remaining
child on the path. All call paths in the graph are re-wired in this manner.
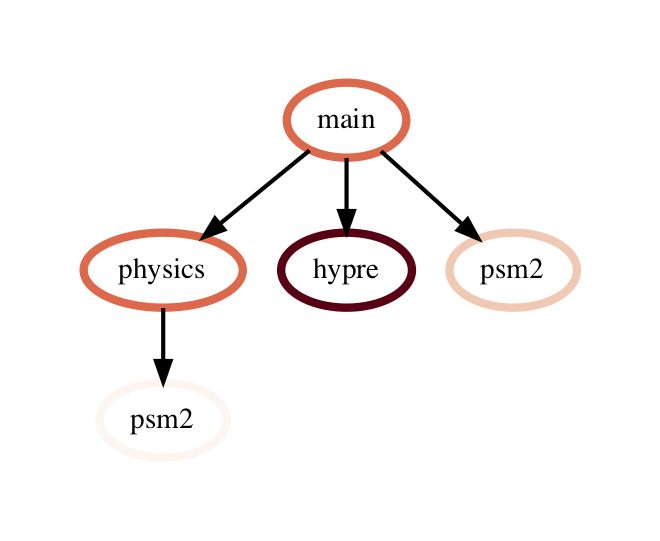
A squash operation creates a new DataFrame in addition to the new graph. The
new DataFrame contains all rows from the original DataFrame, but its index
points to nodes in the new graph. Additionally, a squash operation will make
the values in all columns containing inclusive metrics inaccurate, since the
parent-child relationships have changed. Hence, the squash operation also calls
calculate_inclusive_metrics to make all inclusive columns in the DataFrame
accurate again.
filtered_gf = gf.filter(lambda x: x['time'] > 10.0)
squashed_gf = filtered_gf.squash()
equal: The == operation checks whether two graphs have the same nodes
and edge connectivity when traversing from their roots. If they are
equivalent, it returns true, otherwise it returns false.
union: The union function takes two graphs and creates a unified graph,
preserving all edges structure of the original graphs, and merging nodes with
identical context. When Hatchet performs binary operations on two GraphFrames
with unequal graphs, a union is performed beforehand to ensure that the graphs
are structurally equivalent. This ensures that operands to element-wise
operations like add and subtract, can be aligned by their respective nodes.
GraphFrame operations
copy: The copy operation returns a shallow copy of a GraphFrame. It
creates a new GraphFrame with a copy of the original GraphFrame’s DataFrame,
but the same graph. As mentioned earlier, graphs in Hatchet use immutable
semantics, and they are copied only when they need to be restructured. This
property allows us to reuse graphs from GraphFrame to GraphFrame if the
operations performed on the GraphFrame do not mutate the graph.
deepcopy: The deepcopy operation returns a deep copy of a GraphFrame.
It is similar to copy, but returns a new GraphFrame with a copy of the
original GraphFrame’s DataFrame and a copy of the original GraphFrame’s graph.
unify: unify operates on GraphFrames, and calls union on the two
graphs, and then reindexes the DataFrames in both GraphFrames to be indexed by
the nodes in the unified graph. Binary operations on GraphFrames call unify
which in turn calls union on the respective graphs.
add: Assuming the graphs in two GraphFrames are equal, the add (+)
operation computes the element-wise sum of two DataFrames. In the case where
the two graphs are not identical, unify (described above) is applied first
to create a unified graph before performing the sum. The DataFrames are copied
and reindexed by the combined graph, and the add operation returns new
GraphFrame with the result of adding these DataFrames. Hatchet also provides an
in-place version of the add operator: +=.
subtract: The subtract operation is similar to the add operation in that
it requires the two graphs to be identical. It applies union and reindexes
DataFrames if necessary. Once the graphs are unified, the subtract operation
computes the element-wise difference between the two DataFrames. The subtract
operation returns a new GraphFrame, or it modifies one of the GraphFrames in
place in the case of the in-place subtraction (-=).
gf1 = ht.GraphFrame.from_literal( ... )
gf2 = ht.GraphFrame.from_literal( ... )
gf2 -= gf1
 -
-  =
= 
tree: The tree operation returns the graphframe’s graph structure as a
string that can be printed to the console. By default, the tree uses the
name of each node and the associated time metric as the string
representation. This operation uses automatic color by default, but True or
False can be used to force override.
Chopper API
Analyzing a Single Execution
to_callgraph: For some analyses, the full calling context
of each function is not necessary. It may be more intuitive to examine the
call graph which merges all calls to the same function name into a single
node. The to_callgraph function converts a CCT into a call graph by
merging nodes representing the same function name and summing their associated
metric data. The output is a new GraphFrame where the graph has updated
(merged) caller-callee relationships and the DataFrame has aggregated metric
values.
import hatchet as ht
%load_ext hatchet.vis.loader
gf = ht.GraphFrame.from_literal(simple_cct)
%cct gf # PerfTool's Jupyter CCT Visualization
callgraph_graphframe = gf.to_callgraph()
flatten: This function is a generalized version of
to_callgraph. Rather than merging all nodes associated with the same
function name, it enables users to merge nodes by a different non-numeric
attribute, such as file name or load module. The user provides the column to
use and Chopper merges the nodes into a graph. The resulting graph is not a
call graph however as by definition, a call graph represents caller-callee
relationships between functions.
load_imbalance: Load imbalance is a
common performance problem in parallel programs. Developers and application
users are interested in identifying load imbalance so they can improve the
distribute of work among processes or threads. The load_imbalance
function in Chopper makes it easier to study load imbalance at the level of
individual CCT nodes.
The input is a GraphFrame along with the metric on which to compute imbalance. Optional parameters are a threshold value to filter out inconsequential nodes and a flag for calculate detailed statistics about the load imbalance. The output is a new GraphFrame with the same graph object but additional columns in its DataFrame to describe load imbalance and optionally the verbose statistics.
To calculate per-node load imbalance, pandas DataFrame operations are used to compute the mean and maximum of the given metric across all processes. Load balance is then the maximum divided by the mean. A large maximum-to-mean ratio indicates heavy load imbalance. The per-node load imbalance value is added as a new column in DataFrame.
The threshold parameter is used to filter out nodes with metric values below the given threshold. This feature allows users to remove nodes that might have high imbalance because their metric values are small. For example, high load imbalance may not have significant impact on overall performance in the time spent in the node is small.
The verbose option calculates additional load imbalance statistics. If enabled, the function adds a new column to the resulting DataFrame with each of the following: the top five ranks that have the highest metric values, values of 0th, 25th, 50th, 75th, and 100th percentiles of each node, and the number of processes in each of ten equal-sized bins between the 0th (minimum across processes) and 100th (maximum across processes) percentile values.
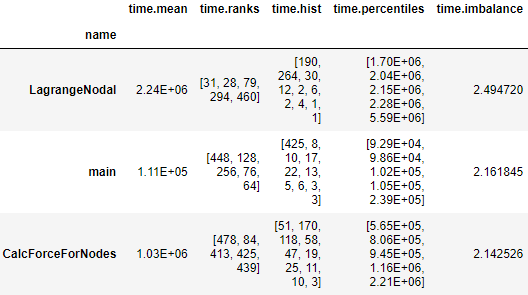
import hatchet as ht
gf = ht.GraphFrame.from_caliper("lulesh-512cores")
gf = gf.load_imbalance(metric_column="time", verbose=True)
print(gf.dataframe)
gf = ht.Chopper.load_imbalance(metric_column="time", verbose=True)
hot_path: A common task in analyzing a single execution
is to examine the most time-consuming call paths in the program or some subset
of the program. Chopper’s hot_path
function retrieves the hot path from any subtree of a CCT given its root. The
input parameters are the GraphFrame, metric (and optional stopping condition),
and the root of the subtree to search. Starting at the given subtree root, the
method traverses the graph it finds a node whose metric accounts for more than a
given percentage of that of its parent. This percentage is the stopping
condition.
The hot path is then the path between that node and the given subtree
root. The function outputs a list of nodes using which the DataFrame can
be manipulated.
By default, the hot_path function uses the most time-consuming root
node (in case of a forest) as the subtree root. The default stopping condition
is 50%. The resulting hot path can be visualized
in the context of the CCT using the interactive Jupyter visualization in
hatchet.
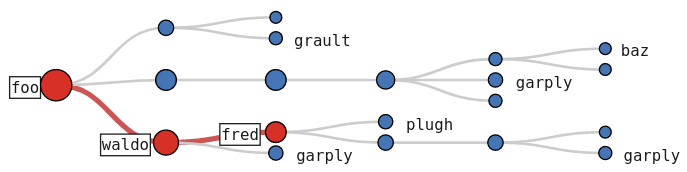
import hatchet as ht
%load_ext hatchet.vis.loader
gf = ht.GraphFrame.from_hpctoolkit("simple-profile")
hot_path = gf.hot_path()
%cct gf #Jupyter CCT visualiation
The image shows the hot path for a simple CCT example, found with a single Chopper function call (line 5) and visualized using hatchet’s Jupyter notebook visualization (line 6). The red-colored path with the large red nodes and additional labeling represents the hot path. Users can interactively expand or collapse subtrees to investigate the CCT further.
Comparing Multiple Executions
construct_from: Ingesting multiple datasets is the first
step to analyzing them. It is laborious and tedious to specify and load each profile
manually, which is necessary in hatchet. To alleviate this
problem, the construct_from function takes a list of datasets
and returns a list of GraphFrames, one for each dataset. Users can then
leverage Python’s built-in functionalities to create the list from names and
structures inspected from the file system.
construct_from automatically detects the data collection source of each
profile, using file extensions, JSON schemes, and other characteristics of the
datasets that are unique to the various output formats. This allows Chopper to
choose the appropriate data read in hatchet for each dataset, eliminating the
manual task of specifying each one.
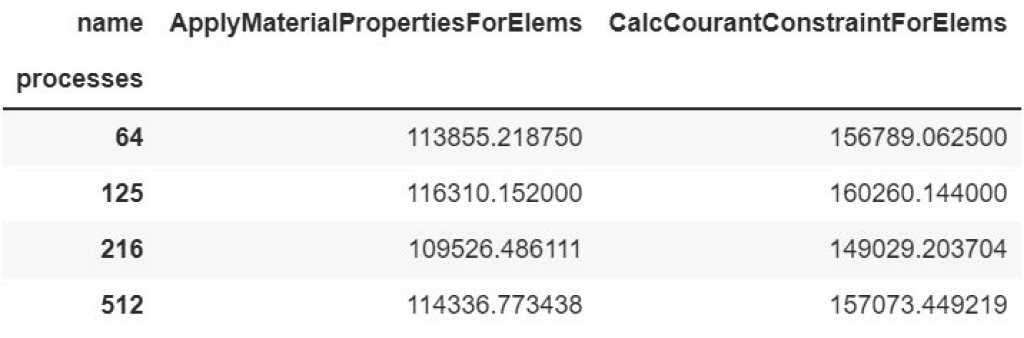
datasets = glob.glob("list_of_lulesh_profiles")
gfs = hatchet.GraphFrame.construct_from(datasets)
table = hatchet.Chopper.multirun_analysis(gfs)
print(table)
multirun_analysis: Analyzing across multiple executions
typically involves comparing metric values across the individual CCT nodes of
the different executions. Implementing this manually can be cumbersome,
especially as CCTs will differ between runs. This task is simplified with the
multirun_analysis function.
By default, multirun_analysis builds a unified “pivot table” of the
multiple executions for a given metric. The index (or “pivot”) is the
execution identifier. Per-execution, the metrics are also aggregated by the
function name. This allows users to quickly summarize across executions and
their composite functions for any metric.
multirun_analysis allows flexibly setting the desired index, columns
(e.g., using file or module rather than function name), and metrics with which
to construct the pivot table. It also provides filtering of nodes below a
threshold value of the metric. The code block above for construct_from demonstrates
multirun_analysis with default parameters (line 3) and its resulting table.
speedup_efficiency: Two commonly used metrics to
determine the scalability of parallel codes are speedup and efficiency.
The speedup_efficiency function simplifies the task of
calculating these metrics per CCT node across multiple executions with different process or
thread counts. Given multiple GraphFrames as input, speedup_efficiency creates a
new DataFrame with efficiency or speedup per CCT node, using unify_multiple_graphframes
to unify the set of nodes. An optional parameter
allows users to set a metric threshold with which to exclude unnecessary nodes.
Speedup and efficiency have different expressions under the assumption of weak
or strong scaling. Thus, the speedup_efficiency functions should be
supplied with the type of experiment performed (weak or strong scaling) and
the metric of interest (speedup or efficiency).
The image below shows the output DataFrame of efficiency values from a weak scaling (64 to 512 process) experiment of LULESH along with the corresponding code block (line 3). The DataFrame can then be used directly to plot the results.
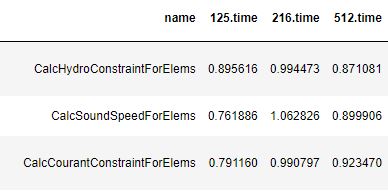
datasets = glob.glob("list_of_lulesh_profiles")
gfs = perftool.GraphFrame.construct_from(datasets)
efficiency = perftool.Chopper.speedup_efficiency(gfs, weak=True, efficiency=True)
print(efficiency.sort_values("512.time", ascending=True))